AI知識運用ガイド
多くの文書をアップロードすることと、AIエージェントが仕事をできるように会社知識を整理することは違います。良いエージェントには、目的、通常手順、例外、判断基準、禁止事項、出典、更新責任者が見える知識が必要です。
1. 概要: 文書アップロードは知識設計ではない
最初のAIエージェント業務を選んだ後、チームが次に聞くのはたいてい「エージェントに何を読ませるか」です。簡単な答えは、Wiki、Driveフォルダ、Notionページ、Slack要約、過去の議事録をすべて入れることです。しかしそれでは、単語は検索できても運用判断ができない状態になりがちです。
OpenAIのfile search文書は、文書を解析し、chunkに分け、embeddingを作り、keyword searchとsemantic searchを使い、関連結果を再ランキングして回答に使う流れを説明しています。GoogleやMicrosoftも、指定したデータソースでエージェントをgroundingする方法を説明しています。これらは検索を可能にします。しかし会社知識そのものが明確で、最新で、権限に合い、判断しやすい形であることは保証しません。
オペレーター向けの実務ルールは単純です。知識ソースをエージェントに接続する前に、その仕事を読める運用カードに変えます。カードにはworkflowの目的、処理手順、重要な例外、人間に聞く基準、絶対にしてはいけない行動、各ルールの出典が必要です。
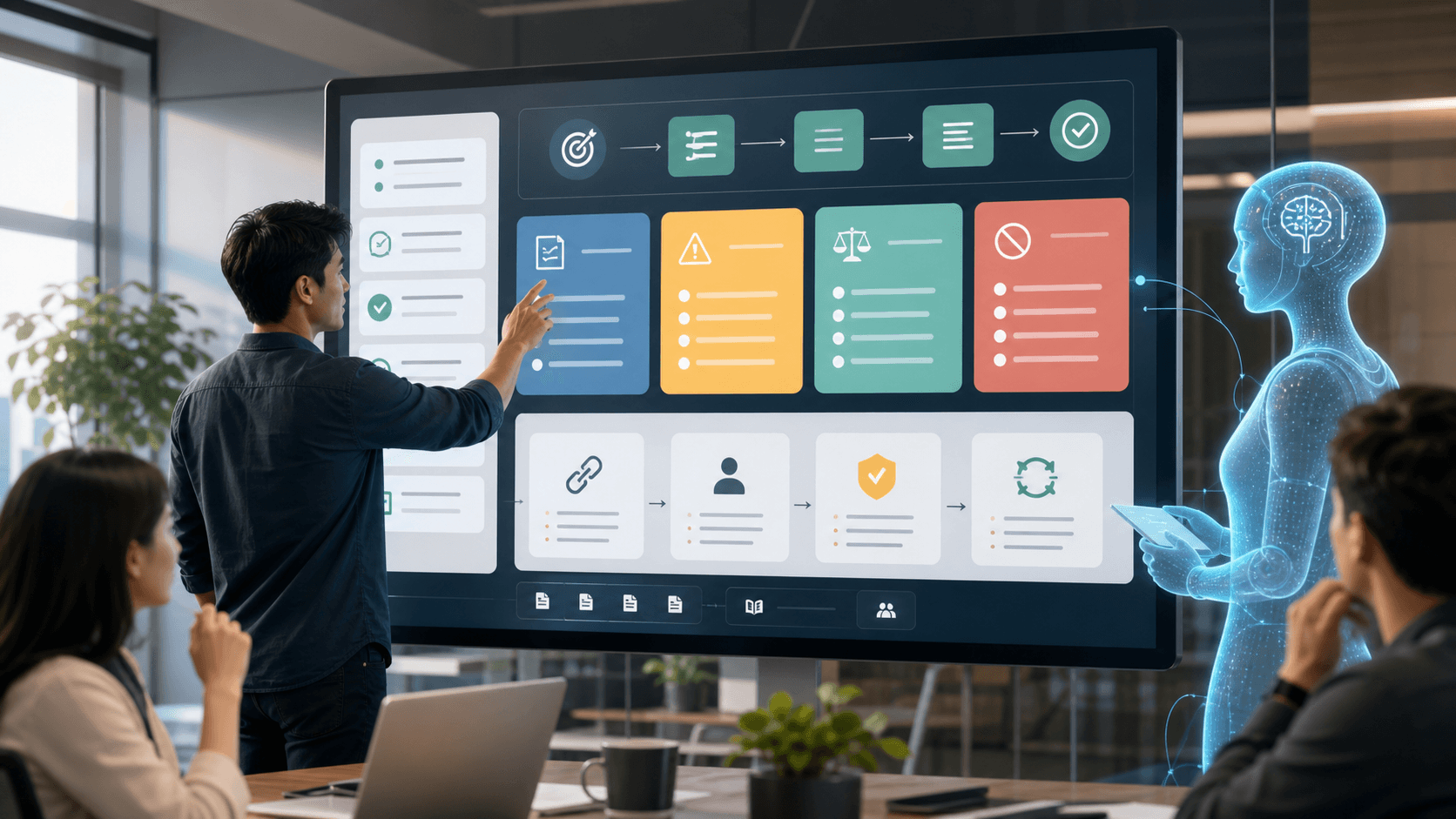
2. AIが読みやすい会社知識の五つの要素
AIが読みやすい知識には五つの要素があります。一つ目は目的です。このworkflowがなぜ存在し、良い結果が何かを示します。二つ目は手順です。熟練した社員が普段たどるステップです。三つ目は例外です。通常ルールが破れるケースです。
四つ目は判断基準です。複数の選択肢からどの道を選ぶかを決める信号です。五つ目は禁止事項です。ユーザーが頼んでも、データが見えても、モデルが自信ありに見えても、エージェントがしてはいけない行動です。
これが重要なのは、エージェントが単に質問に答えるだけではないからです。分類し、ルーティングし、下書きを作り、要約し、推薦し、ときにはtoolを呼びます。知識が「返金は慎重に処理」とだけ書かれていれば、運用境界は見えません。「この条件では返金文だけ下書きし、この金額以上はエスカレーションし、承認なしに返金を実行しない」と書けば、より安全な範囲で動けます。
- 目的: 事業成果と品質基準。
- 手順: 通常の段階的な処理経路。
- 例外: 特殊な顧客、ポリシー衝突、欠落情報、境界ケース。
- 判断基準: どの経路を選ぶか決める信号。
- 禁止事項: 承認やエスカレーションなしにしてはいけない行動。
3. 用語をやさしく言う: SOP, CLAUDE.md, RAG, grounding, citation, freshness
SOPはstandard operating procedureの略です。簡単に言うと、会社の業務レシピです。良いSOPはチェックリストだけではありません。目的、例、例外、承認基準、曖昧なときの処理まで含みます。
CLAUDE.mdのようなファイルはAI briefingです。プロジェクトの安定したルールをAIに伝えます。チームがどう働くか、どのコマンドが重要か、どのスタイルに従うか、どのリスクを避けるか、どのファイルを見るかを書きます。ただしこれは文脈であり、強制装置ではありません。権限、承認、ログ、evalはまだ必要です。
RAGはretrieval-augmented generationの略です。事業の言葉では、AIが答える前に会社知識を検索する方式です。groundingは、回答が出典に結びついていることです。citationは人間が確認できる出典リンクや文書位置です。freshnessは、その出典がまだ最新かを示す日付や責任者情報です。
- SOP: 業務レシピと判断基準表。
- CLAUDE.md: AIへの常設業務ブリーフィング。法的な制御ではありません。
- RAG: 会社知識を先に検索してから答える方式。
- grounding: 一般知識ではなく出典に基づく回答。
- citation: 人間が確認できる回答の根拠。
- freshness: そのルールがまだ有効かを示す日付と責任者。
4. 通常手順より例外ケースが重要
多くのチームはhappy pathから文書化します。それも必要ですが、AIエージェントは境界で揺れます。特殊な顧客、欠落した項目、ポリシー衝突、古い契約、VIP例外、急ぎだが怪しい依頼、Aに見えるがBとして処理すべきケースが問題になります。
Anthropicのcontext engineering記事は、エージェントに必要なのは全コーパスを丸ごと入れることではなく、適切な瞬間に関連する文脈を与えることだと説明しています。会社知識も同じです。エージェントには境界を教える例と反例が必要です。
顧客返信エージェントなら、「丁寧に答える」だけでは足りません。いつ謝るか、いつ追加情報を求めるか、いつ断るか、いつエスカレーションするか、いつ約束を避けるかを例で入れます。良い例外ケース数個は、曖昧なポリシー20ページより安定性を上げることがあります。
- 例: すべての情報がある通常の返金依頼。
- 反例: 承認上限を超える返金依頼。
- 反例: 顧客がポリシー例外を求める場合。
- 反例: 出典文書と最新のお知らせが矛盾する場合。
- 反例: 下書きには十分だが実行権限はない場合。
5. 良い文書構造: 一枚のworkflowカード、例、出典の流れ
最初の導入では巨大な知識ベースを作らない方がよいです。一つのworkflow cardから始めます。このカードは一画面で見え、深い文書は必要な場所だけにリンクします。そうすればエージェントとレビュアーが同じ基準を見られます。
良いworkflow cardには、オーナー、最終更新日、出典リンク、workflow目的、入力項目、通常手順、例、例外、承認基準、禁止事項、出力形式、エスカレーション経路が入ります。レビュアーはこのカードを見て、エージェントが正しいルールを使ったか判断できる必要があります。
Microsoft Copilot Studioの文書は、知識ソースをスコープ化してgroundingでき、ユーザー認証がどのコンテンツを表示するかに影響することを説明しています。小さな会社でも同じ原則を使えます。すべての文書を一つの開いたバケットに入れず、機密、古い、役割別の知識は範囲を分けます。
- 巨大なcompany brainではなく、workflowごとのカード一枚。
- 出典のないコピーではなく、原本リンクのあるルール。
- 抽象ルールだけでなく例と反例。
- 別フォルダに隠れた承認基準ではなく、業務カード内の承認/エスカレーションルール。
- 名前のある更新責任者と最終レビュー日。
6. 悪い文書構造: 長い議事録、古いWiki、隠れた暗黙知
悪いAI知識は外から見ると豊富に見えます。文書が多く、チャンネルが多く、フォルダが多く、過去の決定も多い。しかし問題は、二つの出典が矛盾したときにどちらのルールが勝つか分からないことです。
長い議事録は特に危険です。アイデア、決定、冗談、反対意見、廃止された計画が混ざっているからです。古いWikiは公式に見えるのに間違っているため、さらに危険です。暗黙知も別の失敗を作ります。エージェントは文書基準で答えるが、本当の会社ルールは一人のベテランの頭の中にあるかもしれません。
実際のAI agent workflowに関するReddit議論でも似た問題が繰り返されます。文脈が少なすぎるとhallucinationが起き、多すぎると重要な信号が埋もれ、インデックスが古いとRAGが壊れます。これはコミュニティ信号として扱いますが、運用上の教訓は明確です。知識品質は文書数ではなく、現在有効なルールをどれだけ早く見つけられるかです。
- 悪い: 「すべての議事録を読んで判断して」。
- 良い: 「承認済みの返金SOPを先に使い、議事録は背景としてのみ参照して」。
- 悪い: 「すべての文書をすべてのエージェントが見られる」。
- 良い: 「このworkflowはこの出典だけを読み、使った出典を必ず表示する」。
- 悪い: 「チームは例外を知っている」。
- 良い: 「例外が文書化され、日付、出典、責任者が付いている」。
7. エージェントに知識を接続する前のチェックリスト
知識ソースを接続する前に、運用上の質問に答えます。エージェントは何を読めますか。文書が矛盾したら何が勝ちますか。検索してはいけない情報は何ですか。SOPは誰が更新しますか。レビュアーは欠けた知識や間違った知識をどう示しますか。エージェントがその知識を正しく使ったか、どのevalで確認しますか。
OpenAIとAnthropicの資料は、instructions、tools、retrieval、context、evals、guardrailsが一緒に動くシステムの方向を示しています。非専門チームでも原理は同じです。会社知識はフォルダではなく、生きた運用レイヤーです。
- 読む境界: このworkflowはどの出典を読めるか。
- 出典優先順位: 二つの文書が矛盾したら何が勝つか。
- プライバシー境界: どのデータはマスキング、除外、ローカル保管が必要か。
- 更新責任者: 現実が変わったら誰がルールを直すか。
- 出典表示ルール: すべての回答が根拠を示すべきか。
- evalセット: どの例でエージェントがルールを正しく使ったか試すか。
- フィードバックループ: レビュアーの修正がどう良いSOPに戻るか。
8. 結論: 本当の準備物はAIが読める運用知識
モデルも重要で、検索システムも重要で、tool stackも重要です。しかし多くの会社の最初のボトルネックはもっと単純です。会社自身が、仕事をAIが読めて人間が監査できる形で書いていないのです。
一つのworkflowから始めましょう。目的、手順、例外、判断基準、禁止事項、出典、責任者、evalケースを書きます。その後でエージェントを接続します。そうして会社知識は文書の山ではなく、運用資産になります。
참고자료
- OpenAI API docs: Agents
- OpenAI API docs: File Search
- Anthropic: Effective context engineering for AI agents
- Anthropic: Equipping agents for the real world with Agent Skills
- Microsoft Learn: Copilot Studio knowledge sources
- Google Cloud: Grounding with your data
- NIST AI Risk Management Framework
- Reddit r/AI_Agents: knowledge layer, trust, provenance signal
- Reddit r/AI_Agents: real workflow context selection signal
- X: local company knowledge graph and MCP signal
- X: repeated context explanation and CLAUDE.md signal
- X: markdown company OS and SOP signal
エージェントを接続する前に、会社知識を読める形にする
Guildex Fit Checkは、一つのworkflowをAIが読みやすい運用カードに変えます。目的、SOP、例外、判断基準、禁止事項、出典、更新責任者、承認境界、evalケースを一緒に整理します。